Hilfreiche Werkzeuge¶
Im folgenden werden kurz einige Programme beschrieben, die bei der Entwicklung von C-Programmen hilfreich sein können. Bei den meisten Linux-Systemen (Debian, Ubuntu, Linux Mint) lassen sich diese unmittelbar mittels apt installieren:
aptitude install astyle cdecl cflow doxygen gdb graphviz splint valgrind
Anschließend können die jeweiligen Programme mittels einer Shell im Projekt-Verzeichnis aufgerufen beziehungsweise auf Quellcode-Dateien angewendet werden.
astyle – Code-Beautifier¶
Das Programm astyle kann verwendet werden, um C-Code in eine einheitliche
Form zu bringen. Die Syntax dafür lautet:
astyle option < sourcefile > output_file
Als Option kann mittels -A1 bis -A12 ein gewünschter Code-Style
angegeben werden. Eine Übersicht über die möglichen Style-Varianten ist in der
Dokumentation des
Programms zu finden. In den Beispielen dieses Tutorials wird der Codestyle
„Allman“ (Option -A1) verwendet.
Um beispielsweise alle c-Dateien eines Verzeichnisses mittels astyle in
den gewünschten Code-Style zu bringen, kann folgendes Mini-Skript verwendet
werden (die existierenden Dateien werden dabei ueberschrieben, bei Bedarf vorher
Sicherheitskopie anlegen!):
for i in *.c ; \
do astyle -A1 < $i > $(basename $i).tmp && mv $(basename $i).tmp $i; \
done
cdecl – Deklarations-Übersetzer¶
Das Programm cdecl kann verwendet werden, um komplexe Deklarationen, auf die
man beispielsweise beim Lesen von Quellcode stoßen kann, in einfachem Englisch
zu beschreiben. Umgekehrt kann man durch die Angabe eines Strukturtyps in
entsprechender Englisch-Syntax die entsprechende C-Deklaration zu erhalten.
Üblicherweise wird cdecl mittels der Option -i im interaktiven Modus
gestartet:
cdecl -i
Anschließend kann durch Eingabe von explain und einer beliebigen
C-Deklaration diese in einfachem Englisch angezeigt werden, beispielsweise
liefert explain int myfunc(int, char *); als Ergebnis: declare myfunc as
function (int, pointer to char) returning int. Umgekehrt kann declare in
Verbindung mit einer solchen Englisch-Syntax aufgerufen werden, um C-Code zu
erhalten, beispielsweise liefert declare mylist as array 20 of pointer to
char das Ergebnis char *mylist[20].
Mit help kann Hilfe angezeigt werden, mit quit wird cdecl wieder
beendet.
cflow – Funktionsstruktur-Viewer¶
Mittels cflow kann angezeigt werden, welche Funktionen schrittweise von
einer Quelldatei aufgerufen werden, und falls es sich um externe Funktionen
handelt, in welcher Datei und an welcher Stelle sich diese befinden.
Die Syntax von cflow lautet:
cflow quelldatei.c
doxygen – Dokumentations-Generator¶
Mittels doxygen kann eine Dokumentation eines C-Projekts erzeugt werden,
ohne dass innerhalb der Code-Dateien irgendeine Markup-Sprache verwendet werden
muss. Dafür werden beispielsweise Übersichts- und Strukturdiagramme automatisch
erzeugt, sofern auch das Programm graphviz installiert ist.
Um eine Dokumentation mit Doxygen zu erstellen, wechselt man in das
Projektverzeichnis und gibt doxygen -g Doxyfile ein, um eine
Konfigurationsdatei (üblicherweise: Doxyfile) zu generieren. Die erzeugte
Beispieldatei ist anhand vieler Kommentare weitgehend selbst erklärend und kann
einfach mit einem Texteditor bearbeitet werden; unnötige Kommentare oder
Optionen können dabei zur besseren Übersicht gelöscht werden. Alternativ kann
man eine leere Doxyfile erzeugen und darin wichtige Optionen aktivieren.
Möchte man die von doxygen erstellte Dokumentation in einem eigenen Ordner
abgelegt haben, so sollte man zudem beispielsweise mittels mkdir doxygen im
Projektverzeichnis einen neuen Unterordner erstellen.
Als Optionen zur Erzeugung von C-Code-Übersichten halte ich für sinnvoll:
| Option in der Doxyfile | Beschreibung |
PROJECT_NAME = Toolname |
Namen des Projekts angeben |
OUTPUT_DIRECTORY = ./doxygen |
Verzeichnis für HTML- und LaTeX-Dokumentation festlegen |
OUTPUT_LANGUAGE = German |
Sprache auswählen |
EXTRACT_ALL = YES |
Alle Informationen des Quellcodes verwenden |
SOURCE_BROWSER = YES |
Immer Links zu den entsprechenden Funktionen und Dateien erzeugen |
HAVE_DOT = YES |
Nützliche Aufrufdiagramme mittels graphviz erzeugen |
CALL_GRAPH = YES |
Funktionsaufrufe als Graphen erzeugen |
CALLER_GRAPH = YES |
Als Graphen darstellen, von wo aus die einzelnen Funktionen aufgerufen werden |
FILE_PATTERNS = *.c *.h |
Alle .c und .h-Dateien berücksichtigen |
Nach dem Anpassen der Doxyfile muss im Projektpfad nur doxygen ohne
weiteren Argumente aufgerufen werden, um die Dokumentation zu erstellen und im
doxygen-Unterverzeichnis abzulegen. Anschließend kann man die Indexdatei
./doxygen/html/index.html mit Firefox oder einem anderen Webbrowser öffnen.
gdb – Debugger¶
Fehler übersieht man gerne. Bei der Fehlersuche in C-Code kann der Debugger
gdb eingesetzt werden, um das Verhalten eines Programms schrittweise zu
überprüfen sowie Teile des Quellcodes, die als Fehlerquelle in Frage kommen,
näher eingrenzen zu können.
Um den gdb-Debugger nutzen zu können, muss das zu untersuchende Programm mit
der Option -g oder -ggdb compiliert werden, um für den Debugger
relevante Informationen zu generieren.
# Compilieren zu Debug-Zwecken:
gcc -ggdb -o myprogram myprogram.c
Die Option -ggdb erzeugt ausführlichere, auf gdb zugeschnittene
Informationen und dürfte in den meisten Fällen zu bevorzugen sein.
Anschließend kann das compilierte Programm mit gdb geladen werden:[1]
gdb myprogram
Der Debugger wird dabei im interaktiven Modus gestartet. Um das angegebene
Programm myprogram zu starten, kann run (oder kurz: r) eingegeben
werden; dabei können dem Programm mittels run arg_1 arg_2 ... beliebig viele
Argumente übergeben werden, als ob der Aufruf aus der Shell heraus erfolgen
würde. Das Programm kann dabei abstürzen, wobei eine entsprechende
Fehlermeldung und die für den Absturz relevante Code-Zeile angezeigt wird, oder
(anscheinend) fehlerfrei durchlaufen.
Wird ein Fehler angezeigt, beispielsweise eine „Arithmetic exception“, wenn
versucht wird durch Null zu dividieren, so kann mittels print varname der
Wert der angegebenen Variable zu diesem Zeitpunkt ausgegeben werden.
Verwendung von Breakpoints
Um sich den Programmablauf im Detail anzuschauen, können mit break (oder
kurz: b) so genannte „Breakpoints“ gesetzt werden. An diesen Stellen stoppt
das Programm, wenn es mit run gestartet wird, automatisch. Die Breakpoints
werden von gdb automatisch ausgewählt, beispielsweise werden sie vor
Funktionsaufrufen gesetzt, um mittels print die Werte der übergebenen
Variablen prüfen zu können.
Mittels eines Aufrufs von break num kann auch eine weiterer Breakpoint
unmittelbar vor der Code-Zeile num manuell gesetzt werden. Ist in dem
Programm eine Funktion myfunc() definiert, so werden mittels break
myfunc Breakpoints vor jeder Stelle gesetzt, an denen die angegebene Funktion
aufgerufen wird.
Ist man nach dem Setzen der Breakpoints und dem Aufruf von run am ersten
Breakpoint angekommen, so kann man mittels continue (oder kurz: c) bis
zum nächsten Breakpoint mit der Ausführung des Programms fortfahren.
Alternativ kann next (oder kurz: n) beziehungsweise step (oder kurz:
s) eingegeben werden, um nur die unmittelbar nächste Quellcode-Zeile
auszuführen. Der Unterschied zwischen next und step liegt darin, dass
next die nächste Code-Zeile als eine einzige Anweisung ausführt, während
step im Falle eines Funktionsaufrufs den Code der Funktion zeilenweise
durchläuft.
Drückt man in gdb die Enter-Taste, so wird die unmittelbar vorher
gegebene Anweisung erneut ausgeführt. Dies kann insbesondere in Verbindung mit
next oder step viel Schreibarbeit ersparen.. ;-)
Werte von Variablen beobachten
Ebenso wie Breakpoints die Ausführung des Programms an bestimmten Code-Zeilen
gezielt unterbrechen, kann man mit so genannten „Watchpoints“ das Programm
jedes mal automatisch stoppen, wenn sich der Wert einer angegebenen Variablen
ändert. Befindet sich beispielsweise im Programm eine Variable myvar, so
kann mittels watch myvar ein zu dieser Variablen passender Watchpoint
definiert werden.
Backtraces
Wird eine Funktion aufgerufen, so erzeugt gdb einen so genannten „frame“, in
dem der Funktionsname und die übergebenen Argumente festgehalten werden,
beispielsweise existiert immer ein Frame für die Funktion main, der
gegebenenfalls die beim Aufruf übergebenen Argumente argv sowie ihre Anzahl
argc beinhaltet. Mit jedem Aufruf einer weiteren Funktion wird, solange
deren Ausführung dauert, ein weiterer Frame angelegt.
Tritt ein Fehler auf, so genügt es unter Umständen, wenn die Zeile des Codes
angezeigt wird, die den Fehler verursacht hat. Mitunter ist es jedoch auch gut
zu wissen, wie das Programm zur fehlerhaften Zeile gelangt ist. Dies kann in
gdb mittels einer Eingabe von backtrace (oder kurz: bt) geprüft
werden. Ein solcher Backtrace gibt in umgekehrter Reihenfolge an, durch welche
Funktionsaufruf das Programm an die Fehlerstelle gelangt ist. Somit können
beim nächsten Durchlauf von gdb gezielt Breakpoints gesetzt bzw.
Variablenwerte überprüft werden.
In sehr verschachtelten Programmen können mittels backtrace n nur die
„inneren“ 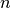 Frames um die Fehlerstelle herum angezeigt werden, mittels
Frames um die Fehlerstelle herum angezeigt werden, mittels
backtrace -n die äußeren Frames.
ddd als graphisches Frontend für gdb
Möchte man gdb mit einer graphischen Oberfläche nutzen, so können
optional die Pakete ddd und xterm via apt installiert
werden:
sudo aptitude install ddd xterm
Anschließend kann man ddd als Debugger-Frontend aufrufen.
gprof – Profiler¶
Der Profiler gprof kann verwendet werden, um zu untersuchen, wie häufig die
einzelnen Funktionen eines Programms aufgerufen werden und wie viel Zeit sie
dabei für ihre Ausführung benötigen. Dies soll kurz anhand des folgenden
Beispielprogramms gezeigt werden:
// Datei: gprof_test.c
#include<stdio.h>
void new_func1(void);
void func_1(void)
{
int i;
printf("\n Now: Inside func_1 \n");
for(i=0; i<1000000000; i++)
;
return;
}
static void func_2(void)
{
int i;
printf("\n Now: Inside func_2 \n");
for(i=0 ;i<2000000000; i++)
;
return;
}
int main(void)
{
int i;
printf("\n Now: Inside main()\n");
for(i=0; i<10000000; i++)
;
func_1();
func_2();
return 0;
}
Um gprof nutzen zu können, muss als erstes das zu untersuchende Programm
zunächst mit der Option -pg compiliert werden, um für den Profiler relevante
Informationen zu generieren; als zweites muss das Programm einmal aufgerufen
werden, um die für gprof relevante Datei gmon.out zu erzeugen:
gcc -o gprof_test -pg gprof_test.c
./gprof_test
Anschließend kann der Profiler mittels gprof ./gprof_test aufgerufen werden.
Ruft man gprof allerdings ohne zusätzliche Optionen auf, so wird eine
ziemlich lange Ausgabe auf dem Bildschirm erzeugt, wobei die meisten
beschreibenden Kommentare in den Regel nicht benötigt werden; gprof sollte
daher mit der Option -b aufgerufen werden, um die ausführlichen Kommentare
auszublenden. Verwendet man zusätzlich die Option -p, so wird die Ausgabe
auf ein Minimum reduziert:
gprof -b -p ./gprof_test
# Ergebnis:
# Flat profile:
#
# Each sample counts as 0.01 seconds.
# % cumulative self self total
# time seconds seconds calls s/call s/call name
# 67.28 4.89 4.89 1 4.89 4.89 func_2
# 33.71 7.34 2.45 1 2.45 2.45 func_1
# 0.28 7.36 0.02 main
Bei dieser Ausgabe sieht man auf den ersten Blick, welche Funktion im Laufe des
Programms am meisten Zeit benötigt beziehungsweise wie viel Zeit sie je Aufruf
braucht. Wird anstelle der Option -p die Option -P verwendet, so wird
neben dieser Aufgliederung angezeigt, an welcher Stelle eine Funktion aufgerufen
wird:
gprof -b -P ./gprof_test
# Ergebnis:
# Call graph
#
#
# granularity: each sample hit covers 2 byte(s) for 0.14% of 7.36 seconds
#
# index % time self children called name
# <spontaneous>
# [1] 100.0 0.02 7.34 main [1]
# 4.89 0.00 1/1 func_2 [2]
# 2.45 0.00 1/1 func_1 [3]
# -----------------------------------------------
# 4.89 0.00 1/1 main [1]
# [2] 66.4 4.89 0.00 1 func_2 [2]
# -----------------------------------------------
# 2.45 0.00 1/1 main [1]
# [3] 33.3 2.45 0.00 1 func_1 [3]
# -----------------------------------------------
#
#
# Index by function name
#
# [3] func_1 [2] func_2 [1] main
Unmittelbar im Anschluss an die Optionen -p oder -P kann auch ein
Funktionsname ausgegeben werden, um die Ausgabe von gprof auf die angegebene
Funktion zu beschränken; zudem kann mittels der Option -a die Aufgabe auf
alle nicht als statisch (privat) deklarierten Funktionen beschränkt werden.
make – Compilier-Hilfe¶
Das Shell-Programm make ist ein äußert praktisches Hilfsmittel beim
Compilieren von C-Quellcode zu fertigen Programmen. Die grundlegende
Funktionsweise von make ist unter Linux und Open Source: Makefiles beschrieben.
splint – Syntax Checker¶
Wendet man den Syntax-Prüfer lint oder die verbesserte Variante splint
auf eine C-Datei an, so reklamiert dieser nicht nur Fehler, sondern auch
Stilmängel.
splint quelldatei.c
Bisweilen kann splint auch Code-Zeilen beanstanden, in denen man bewusst
gegen einzelne „Regeln“ verstoßen hat. In diesem Fall muss man das Ergebnis der
Syntax-Prüfung selbst interpretieren und/oder gegebenenfalls Warnungen mittels
der jeweiligen Option abschalten (diese wird bei der Ausgabe von splint
gleich als Möglichkeit mit angegeben).
time – Timer¶
Der Timer time kann verwendet werden, um die Laufzeit eines Programms zu
messen. Dies ist nützlich, um verschiedene Algorithmen hinsichtlich ihrer
Effizienz zu vergleichen. Als Beispiel soll die Laufzeit zweier Algorithmen
verglichen werden, welche alle Primzahlen zwischen 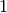 und
und 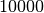 bestimmen sollen:
bestimmen sollen:
// Datei: prim1.c
// (Ein nicht sehr effizienter Algorithmus)
#include <stdio.h>
#define N 10000
int main()
{
int num, factor;
int is_prim;
for(num = 2; num <= N; num++) // Alle Zahlen testen
{
is_prim = 0; // Vermutung: keine Primzahl
for(factor = 2; factor < N; factor++) // Alle möglichen Faktoren ausprobieren
{
if (num % factor == 0) // Test, ob num den Faktor factor enthält
{
if(num == factor) // num ist genau dann Primzahl, wenn sie
is_prim = 1; // nur sich selbst als Faktor enthält
else
break; // sonst nicht
}
}
if (is_prim == 1) // Wenn num Primzahl ist,
printf("%d ", num); // dann Ausgabe auf Bildschirm
}
printf("\n");
return 0;
}
Übersetzt man dieses Programm mittels gcc -o prim1 prim1.c und ruft
anschließend time ./prim1 auf, so erhält man (neben der Auflistung der
Primzahlen) folgende Ausgabe:
gcc -o prim1.c && time ./prim1
# Ergebnis:
# ...
# real 0m0.179s
# user 0m0.175s
# sys 0m0.003s
Die Ausgabe besagt, dass das Programm zur Ausführung insgesamt
![\unit[0,179]{s}](_images/math/4145dce676e508fede23238a4dd5d99d1effe0e3.png) benötigt hat, wobei die zur Ausführung von Benutzer-
und Systemanweisungen benötigten Zeiten getrennt aufgelistet werden. Beide
zusammen ergeben (von Rundungsfehlern abgesehen) die Gesamtzeit.
benötigt hat, wobei die zur Ausführung von Benutzer-
und Systemanweisungen benötigten Zeiten getrennt aufgelistet werden. Beide
zusammen ergeben (von Rundungsfehlern abgesehen) die Gesamtzeit.
Im Vergleich dazu soll ein zweiter, wesentlich effizienterer Algorithmus getestet werden:[2]
// Datei: prim2.c
// (Ein wesentlich effizienterer Algorithmus)
// ("Das Sieb des Eratosthenes")
#include <stdio.h>
#define N 10000
int main()
{
int num = 1;
int factor_1, factor_2;
int numbers[N];
for (numbers[1] = 1; num < N; num++) // Alle Zahlen zunächst
numbers[num] = 1; // als Primzahlen vermuten
for (factor_1 = 2; factor_1 < N/2; factor_1++)
{
for (factor_2 = 2; factor_2 <= N / factor_1; factor_2++)
{
numbers[factor_1 * factor_2] = 0; // Alle möglichen Produkte
} // aus factor_1 und factor_2
// sind keine Primzahlen
}
for (num = 1; num <= N; num++)
{
if (numbers[num] == 1) // Jede verbleibende Zahl 1
{ // entspricht einer Primzahl
printf("%d ", num); // Alle Primzahlen ausgeben
}
}
printf("\n");
return 0;
}
In diesem Fall liefert time nach dem Compilieren folgendes Ergebnis:
gcc -o prim1.c && time ./prim1
# Ergebnis:
# ...
# real 0m0.003s
# user 0m0.002s
# sys 0m0.001s
Der zweite Algorithmus gibt das gleiche Ergebnis aus, benötigt dafür aber nur
rund 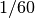 der Zeit. Dieser Unterschied im Rechenaufwand wird noch
wesentlich deutlicher, wenn man in den Quelldateien den Wert
der Zeit. Dieser Unterschied im Rechenaufwand wird noch
wesentlich deutlicher, wenn man in den Quelldateien den Wert N statt auf
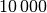 auf
auf 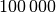 setzt: In diesem Fall ist der erste
Algorithmus auf meinem Rechner erst nach
setzt: In diesem Fall ist der erste
Algorithmus auf meinem Rechner erst nach ![\unit[14.397]{s}](_images/math/9c836b0b22e559cc45454533b0da24b55cb8f992.png) (!!) fertig,
während der zweite nur
(!!) fertig,
während der zweite nur ![\unit[0,032]{s}](_images/math/48f6f289ad8e9c8cd4778217fcee2c9e567b58db.png) benötigt.
benötigt.
valgrind - Speicher-Testprogramm¶
Das Programm valgrind prüft bei einem ausführbaren Programm, wieviel
Speicher dynamisch reserviert bzw. wieder freigegeben wurde.
valgrind programmname
Man kann valgrind auch auf Standard-Programme anwenden, beispielsweise wird
mittels valgrind ps -ax der Speicherbedarf des Programms ps analysiert,
wenn dieses mit der Option -ax aufgerufen wird.
Anmerkungen:
| [1] | Alternativ kann man gdb auch ohne Angabe eines Programmnamens starten
und dieses im interaktiven Modus mittels file myprogram öffnen. |
| [2] | Eratosthenes entwickelte ein einfaches Schema zur Bestimmung aller
Primzahlen kleiner als 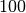 : Zunächst schrieb er die Zahlen in zehn
Zeilen mit je zehn Zahlen auf ein Blatt. Anschließend strich er zunächst
alle geraden Zahlen (jede jede zweite) durch, dann alle durch : Zunächst schrieb er die Zahlen in zehn
Zeilen mit je zehn Zahlen auf ein Blatt. Anschließend strich er zunächst
alle geraden Zahlen (jede jede zweite) durch, dann alle durch 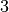 teilbaren Zahlen (also jede dritte), dann alle durch
teilbaren Zahlen (also jede dritte), dann alle durch 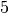 teilbaren
Zahlen (die teilbaren
Zahlen (die 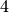 war ja bereits durchgestrichen), usw. Alle
verbleibenden Zahlen mussten Primzahlen sein, denn sie waren nicht als
Vielfache einer anderen Zahl darstellbar. war ja bereits durchgestrichen), usw. Alle
verbleibenden Zahlen mussten Primzahlen sein, denn sie waren nicht als
Vielfache einer anderen Zahl darstellbar. |